Demoing Scaphandre
Tracking power consumption of your computing devices is important. That's why, in this article, we go through another tool that helps you do just that! Join me in the journey of learning about and exploring Scaphandre.
Hi wondering people!
With this article, I again want to walk the walk. So, demo time!
In the last article I wrote about Kepler exporter, what it is, how to use it, and what all those numbers mean. If you missed it, check it out on the link below.
This time, I want to check out the somewhat similar tool called - Scaphandre.
We'll see what it is, how it works, and how can you install it on your machine (in my case Kubernetes cluster). Let's dive in!
What is Scaphandre?
The translation from French - heavy diving suit. In Serbian, it has a bit different meaning. It is also sort of a one-piece suit, that you wear when you go skiing, snowboarding, snowball fighting... If you do an internet search of it, you'll see a plethora of clothing stores offering scaphandres for children.
Sorry, I wandered a bit off-topic. In this context, Scaphandre is a monitoring agent (not just a Prometheus exporter) that tracks energy consumption metrics. It has the same purpose as Kepler - to help measure and understand energy consumption of the services and infrastructure we use.
In their introductory page ask - Why bother with all of this? they give a great answer. You can find it on the link below.


How Scaphandre works?
Following somewhat similar structure as in the previous article, we're now going to dive deeper in how Scaphandre works.
The design of Scaphandre consists of the following:
- Sensors
- Exporters
Sensors
Sensors are there to get the power consumption of the host, and expose it to the exporter part. Based on the documentation, there are two sensors that Scaphandre can use:
- PowercapRAPL sensor - GNU/Linux OS; with Intel or AMD x86 CPUs
- MSRRAPL sensor - Windows 10, Windows Server 2016, and 2019; with Intel or AMD x86 CPUs
These sensors are using the Running Average Power Limit (RAPL) feature on Intel/AMD x86 processors. This feature enables setting the limits on power usage by the CPU and other components. Additionally, it allows us to get the measurements of power consumption of the components. The part of the RAPL measurements are from estimations and models.
We can specify the sensor by adding the -s <SENSOR_NAME> argument to the scaphandre command. Example is below:
scaphandre -s powercap_rapl EXPORTER
Exporters
On the other hand, we have exporters - the part that asks sensor to get new metrics and store them for later usage, and export them. Following is the list of the exporters available in Scaphandre
- JSON
- Prometheus
- Qemu
- Stdout
- Riemann
- Stdout
- Warp10
Each of the above exporters can be called by adding the exporter name to the scaphandre command, like below.
scaphandre prometheus
If you don't specify the -s argument, the default powercap_rapl sensor will be used.
Each of these exporters exports metrics to various source - JSON to json output, Prometheus to an http endpoint, Stdout to standard output.
The Qemu is considered a special exporter though. It computes the energy consumption for each Qemu/KVM virtual machine found on the host.
What metrics are available?
Before I start, I just want to quickly mention metric types available. In Prometheus, we have the following:
- Counter - a cumulative metric that represents a single monotonically increasing counter. Its value can only increase, or be reset to zero on restart. Good for - number of requests served, tasks completed, errors...
- Gauge - a metric that represents a single numerical value, that can go up and down. Good for - temperatures, current memory usage, number of concurrent requests...
- Histogram - samples observations and counts them in configurable buckets. This type of metric exposes multiple time series during scrape.
- Summary - similar to histogram, it samples observations. While it provides a total count and a sum of all observed values, it also calculates the configurable quantiles over a sliding time window.
The most used metric types are counter and gauge.
Now that we got this covered, let's move to the list of the metrics available in Scaphandre. TL;DR it's huge! Therefore, I would only focus on a couple of key metrics computed and available.
scaph_host_power_microwatts- Aggregation of several measurements showing power usage of the whole host, in micro-watts. It is a gauge metric type.scaph_process_power_consumption_microwatts{}- Power consumption of the process, measured on at the topology level, in micro-watts. It is also a gauge metric type.caph_socket_power_microwatts{}- Power measurement relative to a CPU socket, in micro-watts. Also, a gauge.
Besides the above metrics, Scaphandre provides additional metrics related to:
- disk space
- memory usage
- CPU load and frequency
- Scaphandre-specific metrics (to monitor and troubleshoot the tool).
We've covered some basics. Now, let's dive into installing the tool and checking out all these metrics in some Grafana dashboard.
How to install Scaphandre?
There are a couple of ways to install Scaphandre, and I've tested two approaches:
- using Debian package
- using helm and running it on K3s cluster
Installing from debian package
I wanted to test out how the Shaphandre works from the command line. Therefore, I opted for installing it from debian package. First, I needed to download the package from the following URL.
 barnumbirr
barnumbirrThese are the commands I've executed to do so, and install the package.
cd /tmp
# Download the package
curl -LO https://github.com/barnumbirr/scaphandre-debian/releases/download/v1.0.0-1/scaphandre_1.0.0-1_amd64_bookworm.deb
# Install package
sudo apt install ./scaphandre_1.0.0-1_amd64_bookworm.deb
After this completed, I run the scaphandre locally, with the following command.
Note: I needed to run the command with sudo privileges.
$ sudo scaphandre stdout -t 10
# Output
scaphandre::sensors: Sysinfo sees 16
Scaphandre stdout exporter
Sending ⚡ metrics
Measurement step is: 2s
scaphandre::sensors: Not enough records for socket
Host: 0 W from
package core dram uncore
Top 5 consumers:
Power PID Exe
No processes found yet or filter returns no value.
------------------------------------------------------------
Host: 17.233882 W from powercap_rapl_psys
package core dram uncore
Socket0 8.890063 W | 4.670897 W 1.222094 W 0.086669 W
Top 5 consumers:
Power PID Exe
0.009456176 W 284 ""
0.009456176 W 120792 "/app/obsidian"
0.004728088 W 125299 ""
0.004728088 W 5648 "/usr/bin/gnome-shell"
0.004728088 W 126604 "/usr/lib/firefox/firefox-bin (deleted)"
------------------------------------------------------------
Host: 16.354634 W from powercap_rapl_psys
package core dram uncore
Socket0 7.961599 W | 3.708898 W 1.213868 W 0.07227 W
Top 5 consumers:
Power PID Exe
0.02474975 W 5648 "/usr/bin/gnome-shell"
0.0049499497 W 284 ""
0.0049499497 W 130000 ""
0.0049499497 W 4175 "/coredns"
0.0049499497 W 120792 "/app/obsidian"
------------------------------------------------------------
As you can see in the output above, there are some numbers from my laptop. Now, let's see if we can show them on a Grafana dashboard.
Installing from Helm chart
To present the metrics on the Grafana dashboard, I've opted for the installation of Scaphandre via Helm, because I already had the monitoring stack running on my K3s cluster. I did the following.
git clone https://github.com/hubblo-org/scaphandre
cd scaphandre
Before I did the installation of the chart, I needed to update two files. First, the daemonset.yaml with the below lines in the container section. This enables running the pod as privileged.
Note: do not do this in production!
securityContext:
privileged: true
Next, I needed to enable the ServiceMonitor creation in the values.yaml file, in order to make Prometheus aware of the Scaphandre instance.
serviceMonitor:
# Specifies whether ServiceMonitor for Prometheus operator should be created
enabled: true
interval: 1m
# Specifies namespace, where ServiceMonitor should be installed
namespace: monitoring
After I did all the necessary changes, I went ahead and installed Scaphandre.
helm upgrade -i scaphandre helm/scaphandre -n scaphandre --create-namespace
After this finished, I've continued on to add the Grafana dashboard.
Getting the Grafana dashboard
Unlike the Kepler exporter dashboard, this one was rather simple, and partially working, at least on my setup.
I took the json file from the below link, and imported it in Grafana. The end result is shown on the image below.
hubblo-org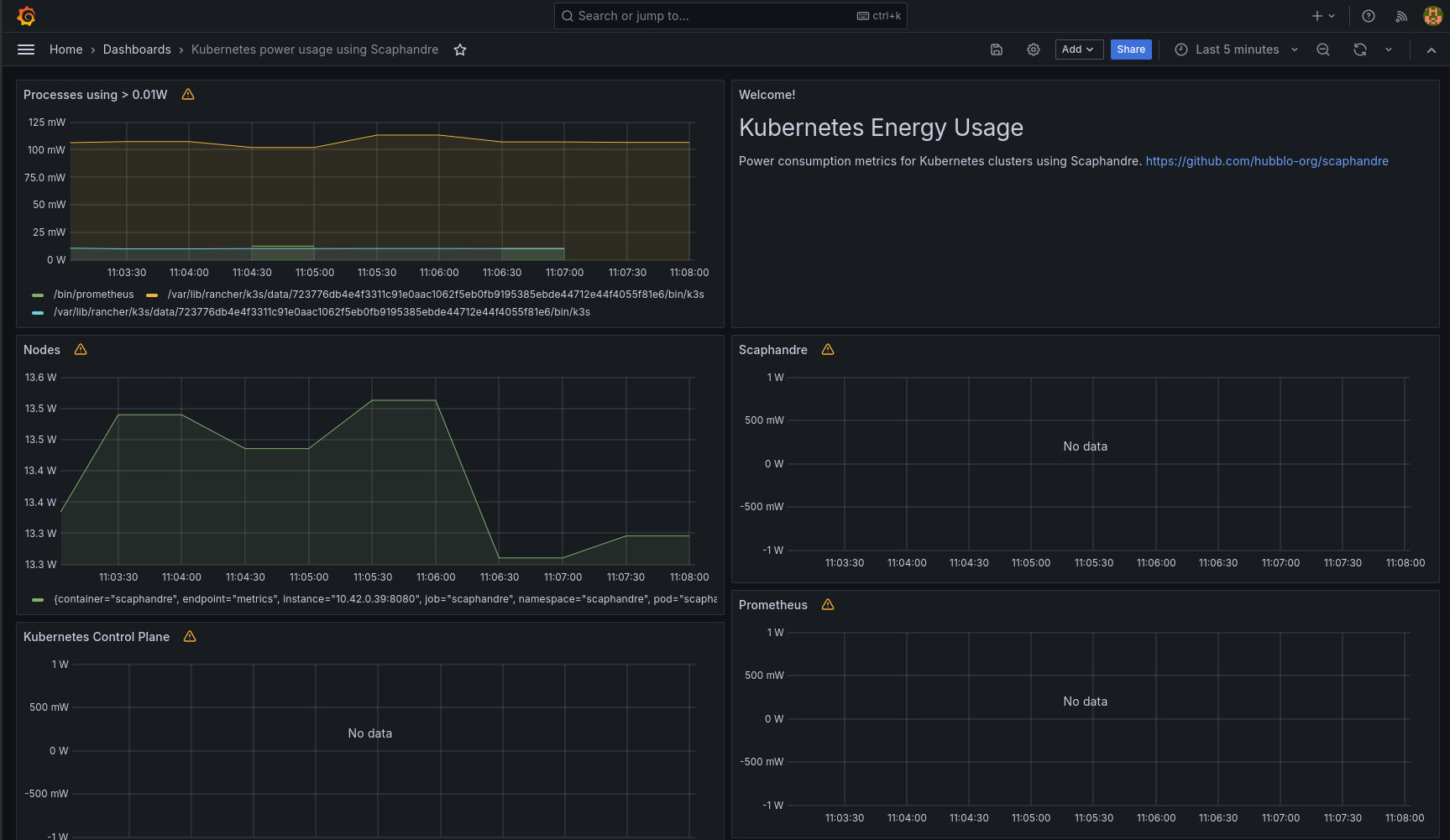
As you can see, the dashboard worked partially, out of the box. But that is not a problem. As long as we have metrics, we can modify it or create a new, more representative one.
Security concerns
Looking from the security perspective - both Scaphandre and Kepler require root permissions to run. This isn't ideal, and for sure to be considered when running in production. If you (unlike myself) know what you're doing, test it out and see how it will run in your production environment.
Running it in Kubernetes will not fix this issue. Both tools were running as DaemonSets, privileged, and mapping local system-based directories, such as /proc and /sys to the pods. Which is considered a no-no by the overall Kubernetes security recommendations.
Summary
Now, to reflect on the Scaphandre installation and setup process. The overall status is the following.
- Scaphandre is not just a Prometheus exporter, it supports different exporters.
- It is possible to run it on Windows, as it supports a Windows-based sensor (although, I didn't test that out).
- Setup and installation is not as straight-forward as with Kepler.
- Scaphandre requires a bit more tuning from the start, compared to Kepler.
- Security concerns need to be taken into account and addressed accordingly, before moving to production.
Congrats! You've reached the end of yet another demo article. If you liked what you see, or want to find out more, check out other Demo articles from my blog.
It would mean a lot to if you shared this article with people interested in the topic of Sustainability in tech!
See you in the next one!